[번역]Reactive Streams로의 여행
Reactive Streams로의 여행
[그림: 현대 시스템에서 데이터는 계속해서 움직인다.]
현대 소프트웨어는 정지 상태에서 데이터를 처리하기보다는 거의 실시간으로 데이터를 처리한다. 빅 데이터는 빠른 데이터보다 덜 중요하며 빠른 정보에는 빠른 데이터가 결정적이다. 스트림 프로세싱(Stream processing)은 모든 사이즈의 데이터 -대, 중, 소-를 가능한 빠르게 정보로 변환하는데 도움이 되는 방법 중 하나이다. 시스템이 움직이는 데이터를 받아 들이면서 전통적인 배치 아키텍처는 순수 스트림 기반 아키텍처로 새롭게 만들어지고 있다. 이러한 시스템에서 살아있는 데이터는 몇 초 또는 그 이하의 응답시간으로 캡처되고 처리되며 행동을 바꾸는데 사용된다. 전통적인 배치 기반 아키텍처가 정보 변환에 응답하는데 몇 시간, 몇 일, 심지어 몇 주가 걸리는 것이 아닌 1초 미만의 응답 시간은 중요한 비즈니스적 가치를 가진다. Reactive Streams과 같은 사양(Specifications)과 Akka와 같은 스트림 처리 라이브러리들은 이러한 시스템을 효율적으로 구현할 때 필요한 표준(standards)과 배관(plumbing)을 제공한다.
스트림 프로세싱의 추상화에 잘 맞는 시스템으로는 ETL(추출, 변환, 로드) 시스템, CEP(복잡한 이벤트 처리) 시스템 그리고 여러 다양한 보고/분석 시스템들이 있다. NoSQL의 진전과 비슷하게, 조직이 생각하는 방식을 그들의 시스템을 통과해 흐르는 데이터를 생각하는 방식으로 뒤집는 것을 약속하는 NoETL 역시 진전되고 있다. 가능성은 끝이 없으며 오직 데이터 집약적 도메인에서 작업을 하는 소프트웨어 개발자의 상상력에 의해서만 제한된다.
스트림 개론
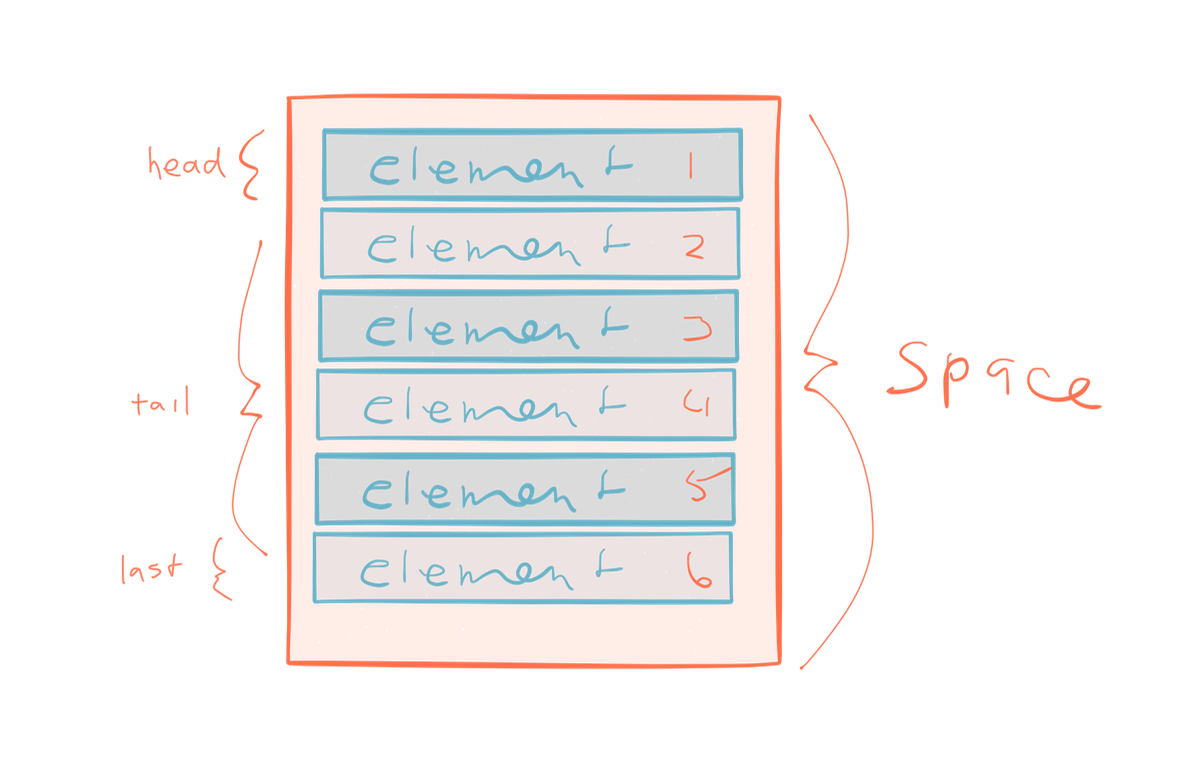
스트림은 시간의 흐름 동안(over time) 발행(emit)되는 일련의 요소들(series of elements)이다. 이 연속(series)은 시작점이 없고 마지막도 없을 가능성이 있다. 일련의 요소들이 메모리에 할당된 배열과는 반대다. 배열은 시작점과 마지막을 가진다.
여기 어떤 시나리오가 있다: 일련의 정수 값들의 평균을 구하기. 요소들의 개수를 알 수 없는 작업의 영향을 생각해보자; 만약 스트림 내부의 요소들의 개수를 모른다면 -그리고 스트림이 끝을 가지고 있지 않을 가능성이 있다면- 어떻게 그리고 언제 평균을 발행할 것인가? 스트림과 컬렉션으로 작업을 할 때는 미묘한 (그리고 그다지 미묘하지 않은) 차이점이 존재한다.
위 일련의 요소들을 배열 대신 스트림으로 시각화해보자. 생산자는 6개의 항목을 발행했다. 우리는 어느 시간 동안 스트림을 붙잡고 그 것들 중 4개를 처리하지만 6번째 항목이 발행되기 전에 분리한다.
이것은 스트림과 배열간의 중요한 차이점을 강조한다 -스트림 처리 시스템에서는 스트림의 모든 단일 요소에 방문하지 않는 것이 가능할 뿐만 아니라 오히려 예상을 할 수 있다. 요소들이 다른 속도로 발행될 뿐만 아니라 -어떨 때는 빠르고, 어떨 때는 조금씩- 많은 경우에 있어 발행된 요소들을 모두 처리하는 것이 보장되지 않는다. 배열은 최종 평균을 반환할 수 있다; 배열은 완전히 메모리에 존재한다. 스트림의 요소들은 아직 나타나지 않았을 수도 있다. 결말(finality)의 개념이 없는 경우 운동, 끊임없이 변화하는 데이터 세트 및 언제나 움직이는 값들에 관해 생각할 필요가 있다. 이 움직임이 어떻게 보여지고 동작하는지를 정의하는 것은 우리에게 달려있다.
당신은 같은 개울(stream)에 발을 두 번 들어 놓을 수 없다. 당신이 발을 들어 놓는 동안 다른 물이 항상 당신에게 흘러 들어온다. -Hearclitus
Reactive Streams 탐험
Reactive Streams는 라이브러리 개발자를 위한 명세(specification)이다. 라이브러리 개발자는 Reactive Streams API를 직접 코딩하지만 비즈니스 시스템을 구축하는 개발자는 Reactive Streams 명세의 구현으로 작업을 할 것이다.
Reactive Streams은 2013년 Netflix, Pivotal 그리고 Typesafe의 엔지니어들의 발의로 2013년 후반에 시작되었다. 가장 초기 토론의 일부는 2013년 Typesafe의 Play 팀과 Akka 팀 사이에서 시작되었다. 이 시점에 스트리밍은 구현하기가 어려웠다. -Play는 “iteratees”를 가지고 있었지만 이는 오직 스칼라만을 위한 것이였고 많은 개발자가 이해하기 어려웠다; Akka는 Akka IO를 가지고 있었지만 이 역시 비즈니스 수준 프로그래밍에서는 너무 복잡했다. 토론은 계속되었고 결국 Roland Kuhn과 Erik Meijer간의 대화로 이어졌다. 이 대화는 비동기 경계를 넘는 데이터 전달을 위한 Rx 기반 접근의 씨앗이 되었다. Viktor Klang은 개발자 커뮤니티의 다른 구성원들에게 손을 내밀었으며 더 큰 발의가 시작되었다. 이 명세(specification)는 곧 GitHub 프로젝트가 되었고 그 후 2015년 5월에 1.0에 도달하였다. Reactive Streams의 역사와 어떻게 함께 오게 되었는지에 대해 더 알고 싶다면 Viktor Klang이 Netflix의 Ben christensen, Pivotal의 Stephane Maldini 그리고 Typesafe의 Dr. Roland Kuhn와 함께한 명세에 대한 그들의 작업에 대한 인터뷰가 있다.
Reactive Streams의 목표는 추상화 수준을 한 단계 높이는 것이다 -비즈니스 개발자가 스트림을 취급하는 저수준 배관 작업을 걱정하는 대신 이 명세 스스로가 이 문제들을 정의한다. 그 뒤에 우리를 위해 이 문제들의 대부분을 처리하는 것은 라이브러리 개발자들의 일이다.
우리는 어떤 스레드도 블록하지 않고도 데이터 수령자(recipients)가 압도되지 않도록 하는 로컬 프로토컬을 정의하려고 시작했지만 결국 적용 범위가 훨씬 더 커졌다; HTTP 페이로드를 서버에서 또는 서버로 스트리밍할 때 TCP의 자연스러운 배압(back-pressure) 전파는 네트워크를 통해 전송하기 전후에 데이터에 수행된 스트림 변환과 매끄럽게 통합되어야 한다. — Dr. Roland Kuhn, Typesafe
만약 당신이 Reactive Streams에 순응하는 라이브러리의 개발자가 아니라 할지라도 Reactive Streams을 이해하는 것은 매우 유용한다. 이것은 스트림 프로세싱 영역의 가장 도전적인 문제들을 정의하고 해결하는 것을 목표로 한다.
위의 내용을 추가하면 우리는 두 가지 핵심 사항 모두 관심을 가진다고 생각한다. 먼저 스트림 구현이 무제한 버퍼링없이 존재할 수 있게 하고 반응형(reactive)과 대화형(interactive) 모델간에 소비율에 기반한 자동적 전환이 가능하게 하기. 둘째로 라이브러리들, 시스템들, 네트워크들 그리고 프로세서들간에 상호 운영(interoperability)을 허용하는 해결법을 원했다. — Ben Christensen, Netflix
Reactive Streams가 해결하고자 하는 핵심 개념들과 과제들을 살펴 보도록 하자.
두 개의 프로세스를 고려해보자. 하나가 다른 것에게 무엇인가를 묻고 그 답을 돌려 받기를 동기적으로 기대한다. 만약 두 번째 프로세스가 대답을 제공하지 않으면 첫번째 프로세스는 중단된다 — “비동기 경계(Asynchronous Boundary)”의 설명, Roland Kuhn
비동기 경계(asynchronous boundary)의 개념이 이 명세의 핵심이다. 본질적으로 비동기 경계는 당신의 시스템의 구성 요소를 분리(decouple)한다.
비동기, 동기, 블로킹, 논-블로킹과 같은 용어에 익숙하지 않다면 Jamie Allen의 블로그 포스트를 읽는 것을 권한다. 그는 접시 씻는 예를 사용하여 위 용어들을 설명한다.
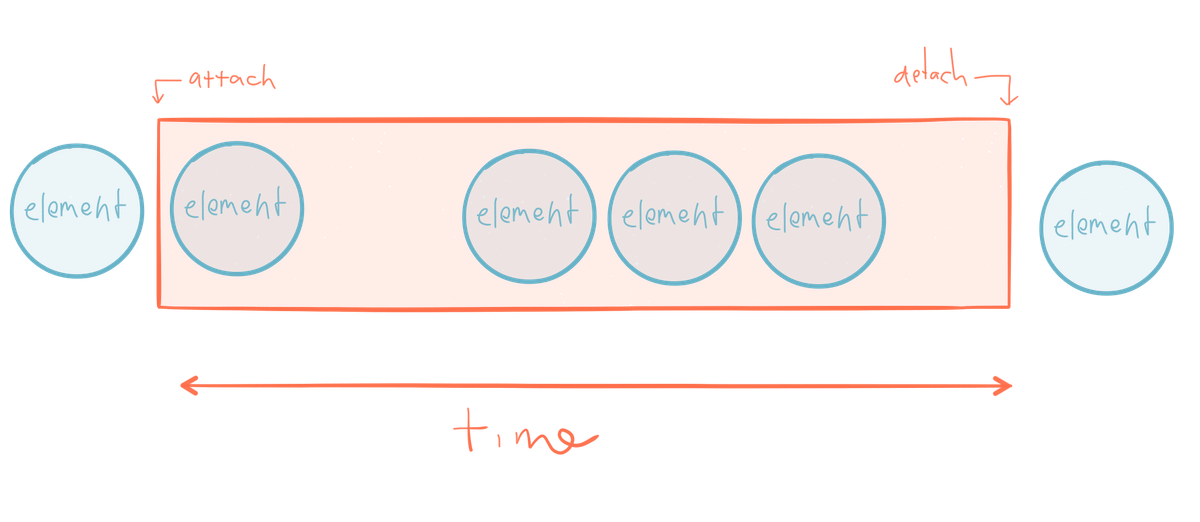
[그림:동기, 순차적 함수 호출]
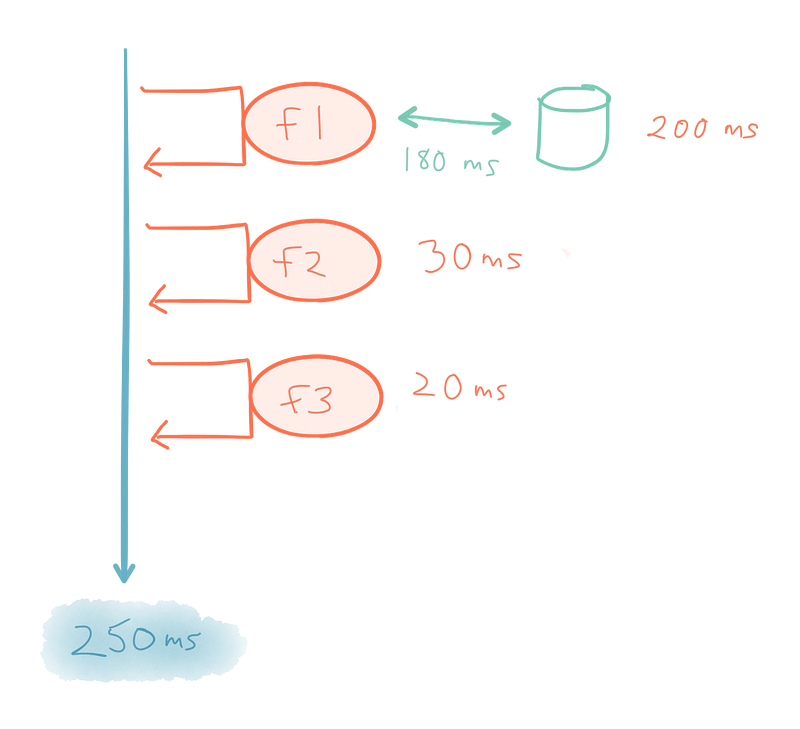
먼저 동기(synchrony)를 탐구하자. 우리가 f1, f2, f3라는 세 가지 함수를 가지고 있다고 가정하자. 각각은 순서대로 하나씩 처리된다. 우리는 특정한 실행 명령에 묶여 있을 뿐만 아니라 각각의 성공은 다른 것의 자비에 달려있다. 예를 들어 f1이 데이터베이스에 시속되는 것 같은 일종의 블로킹 작업을 수행한다고 하자. 이는 f1이 완료될 때 까지 f2와 f3의 진행을 차단한다. 그러므로 전체 흐름의 총 실행 시간은 각 함수의 각 함수의 응답시간의 합(+ 컨텍스트 전환)이다.
동기(synchrony)와 연결(coupling)은 유지 보수의 부담을 유발할 뿐만 아니라 완전히 응답적(responsive) 시스템을 만들기 위한 능력을 감소시킨다. 값비싼 계산을 호출자와 동일한 스레드에서 수행하기, 수신자의 성공적인 응답에 의존하기 등 “응답성 안티-패턴”을 포옹하는 경향이 있다.
예를 들어 f1의 실패는 f2와 f3가 실행되지 않도록 완전히 막는다. f1이 (데이터 베이스에 지속되는) 위험한 작업을 수행한다면 완료가 될 것이라고 기대해서는 안된다 –시스템은 f1이 필연적으로 실패할 때에도 (제한된 기능이지만) 정상적으로 동작할 수 있는 방식으로 디자인 되어야 한다. 동기성은 f2와 f3가 병렬로 수행되는 것도 막는다. f2와 f3가 (블로킹 I/O같은) 부수 효과를 가지지 않는 순수 함수라고 가정하면 f1의 출력을 필요로 하지 않는다. f1이 블록 상태라고 해도 그들이 병렬로 수행되지 말아야 할 이유는 없다.
동기의 다른 예제인 싱글-스레드 이벤트 루프를 보자. 이것은 Node.js같은 이벤트 기반 프레임워크에서 일반적이다 –이벤트들이 발행되고 큐에 담기고 동기적 루프 내부의 이벤트 핸들러에 의해 처리된다. 그리고 이 이벤트들의 수령인은 익명 함수 콜백이다. 이벤트 루프와 같은 스레드에서 블로킹이 발생하면 병목이 일어난다(예를 들면 데이터베이스로의 이동을 시작하는 콜백).
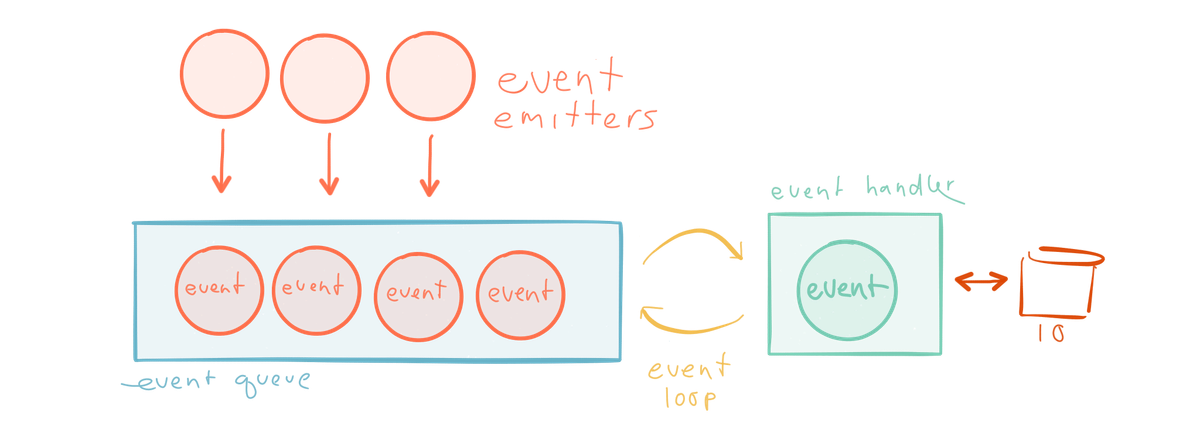
우리가 원하는 대로 쓸 수 있는 자원, 즉 멀티코어 CPU 아키텍처 및 네트워크를 최대한 활용하려면 우리 시스템의 구성 요소들을 분리하기 위한 완전히 다른 모델이 필요하다.
비동기성(asynchrony)은 단일 머신에 있는 다중 CPU나 공동 네트워크 호스트에 있는 계산 자원을 병렬로 사용할 수 있기 위해 필요하다. — http://www.reactive-streams.org
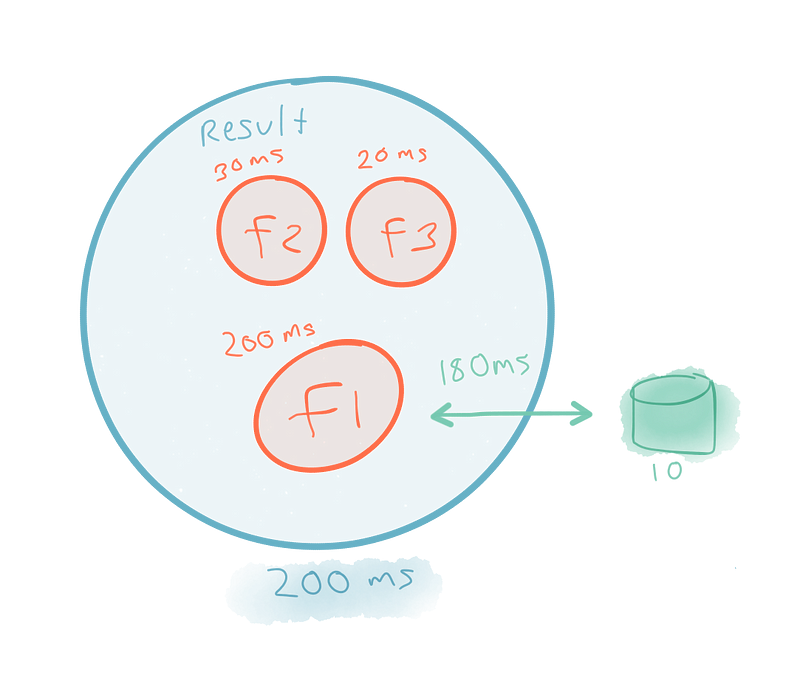
[그림:순차적(sequence) 작업들에 집중하기 대신 함수들을 구성하기(composing)]
실행 순서가 아니라 데이터 구조의 구성 방법의 측면으로 생각을 하면, 성능 향상을 깨닫게 된다. 예를 들어 f2와 f3이 f1과 병렬로 실행되고 완료된다면 f1이 실행을 끝마치는 시점에 전체 결과가 준비된다. 실행 시간은 모든 응답 시간들의 합이 되는 것이 아니라 가장 긴 작업의 응답 시간이 된다.
진짜 적은 블로킹 호출이 아니라 동기 블로킹 호출이다.
배압(back pressure)는 스레드 사이를 중재하는 큐(queue)가 한계를 가지도록 하기 위한 이 모델의 불가결한 부분이다 – http://www.reactive-streams.org
Reactive Streams 명세의 또다른 핵심 목표은 배압(back pressure)을 위한 모델을 정의하는 것이다. 이 것은 빠른 생산자가 느린 구독자를 압도하지 않도록 보증하는 방법이다. 배압(back pressure)은 스트림 기반 시스템의 모든 참석자들이 작업의 고정된 상태와 우아한 쇠퇴를 보증하기 위한 흐름 제어(flow control)에 반드시 참여하게 함을 통해 복원성(resilience)을 제공한다. 이는 라이브러리간의 상호 운영 가능성을 내포한다.
이 섹션의 나머지 부분에서는 발행-구독 패턴에 대해 어느 정도 익숙함을 기대한다.
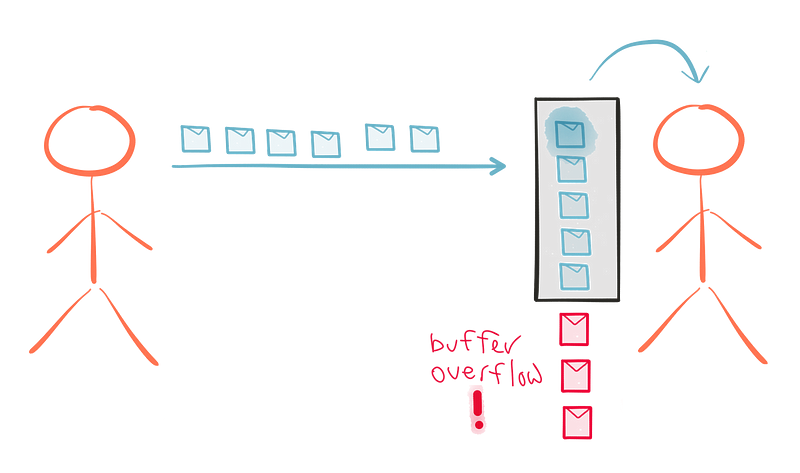
스트림 처리 시스템을 위한 이상적인 패러다임은 데이터를 생산자에서 구독자로 푸시하는 것이다. 이는 생산자가 가능한 빠르게 작업을 할 수 있도록 해준다. 하지만 데이터 흐름이 극대화 되어 시스템의 일부가 쏟아져 들어올 수 있는 시나리오는 상상하는 것은 어렵지 않다. 푸시는 구독자가 생산자보다 빠를 때 잘 동작한다. 하지만 일정 기간 동안 구독자가 게시자보다 더 빠를 것인지의 여부를 매 순간마다 예측하는 것은 상당히 어렵다. 불행히도 대부분의 스트림 처리 시스템은 개발 시점에서 푸시(push)와 풀(pull) 중 하나를 택하도록 강제한다.
이 문제를 처리하기 위한 몇가지 선택지가 있다.
첫번째 해결책은 풀(pull)을 하는 것이다. 이는 느린 구독자(subscriber)가 압도되는 것을 방지한다. 또한 구독자(subscriber)가 생산자(producer)보다 더 빠를 때 시스템의 리소스를 낭비한다. 구독자(subscriber)가 따라가기에 충분한 수용력을 가지고 있을 때 빠른 발행자(publisher)가 최대 속도로 실행되는 것을 방지하기 때문이다.
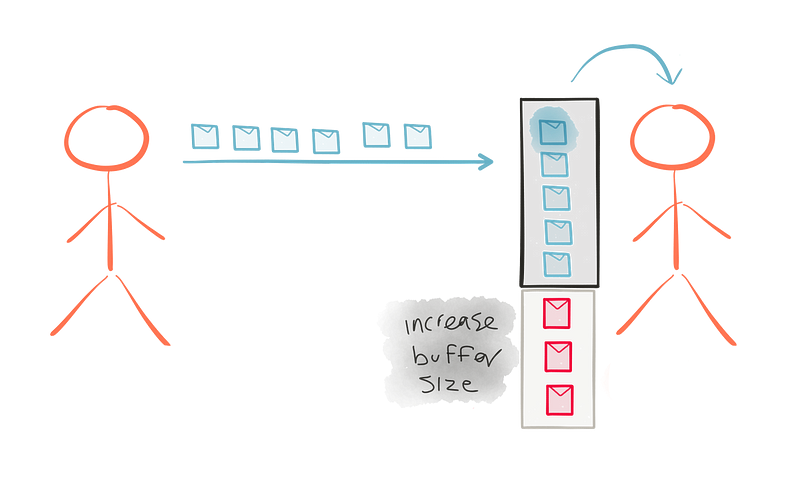
다른 선택지는 구독자의 버퍼 크기를 늘리는 것이다. 가능하지만 항상 현실적이지는 않다. 무제한 메모리를 사용하면 좋겠지만 전체 시스템의 전체에 걸쳐 큐(queue)의 버퍼 크기를 늘려야 한다. 단 하나의 느린 구독자가 버퍼 크기를 늘린 뒤라도 구독자가 넘쳐서 실패할 경우 전체 시스템에 실패가 폭포처럼 쏟아질 위험을 만든다. 메모리 증가 또는 Kafka같은 분산 큐를 사용하여 전략적으로 증가하는 버퍼 크기는 의미가 있지만 이 전략을 전체 흐름의 모든 단계에서 적용하는 것은 그렇지 않다.
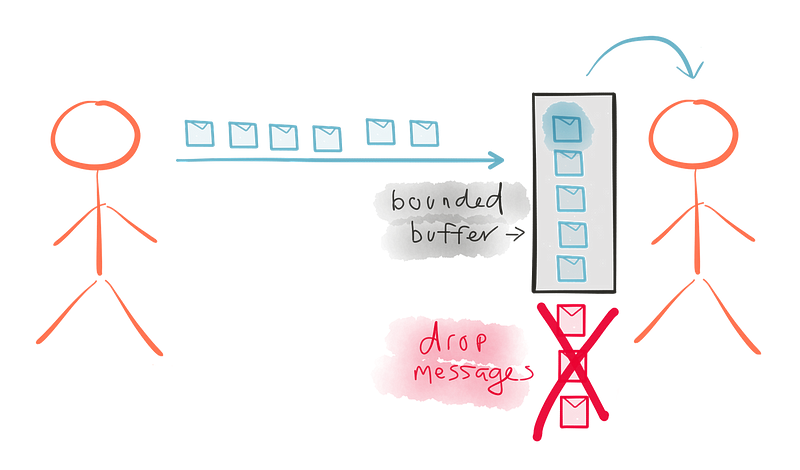
다른 선택지는 단순하게 요소들을 버리는 것이다. 스트림 처리 작업은 처리할 수 없는 것을 버릴 수 있는 어떤 유연성을 제공한다. 하지만 이것이 항상 적절하지는 않다. 예를 들여 초당 1개의 수용량을 가진 구독자 같은 느린 구독자에 대비하여 예를 들어 초당 100개의 요소들을 발행하는 발행자 같은 빠른 발행자에서 발행되는 요소의 용량간의 극도로 다양한 차이를 가진 시스템을 상상해보라. 엄청난 양의 버려진 요소들이 존재한다! 이제 클라우드에 있는 리소스 프로비저닝으로 동적 확장을 한다고 생각해보자. 구독자는 갑자기 초당 200개의 요소를 처리할 수 있다. 우리는 요소를 삭제하는 것에서 부터 모두를 처리하는 것에 이르렀다. 결과의 일관성은 런타임의 조건에 따라 극도라 다양해질 수 있다. 어떤 도메인에서는 허용될 수 있지만 다른 도메인에서는 절대로 허용되지 않는다.
배압(back pressure)는 사용자에게 폭포처럼 쏟아 질 수 있으며, 그 시점에서 응답성이 저하될 수 있다. 하지만 이 메커니즘은 시스템은 부하에 대한 복원적(resilient)임을 보장 할 것이며 시스템 스스로가 부하의 분산을 돕기 위해 다른 리소스들을 활용할 수 있도록 해주는 정보를 제공할 것이다. — The Reactive Manifesto
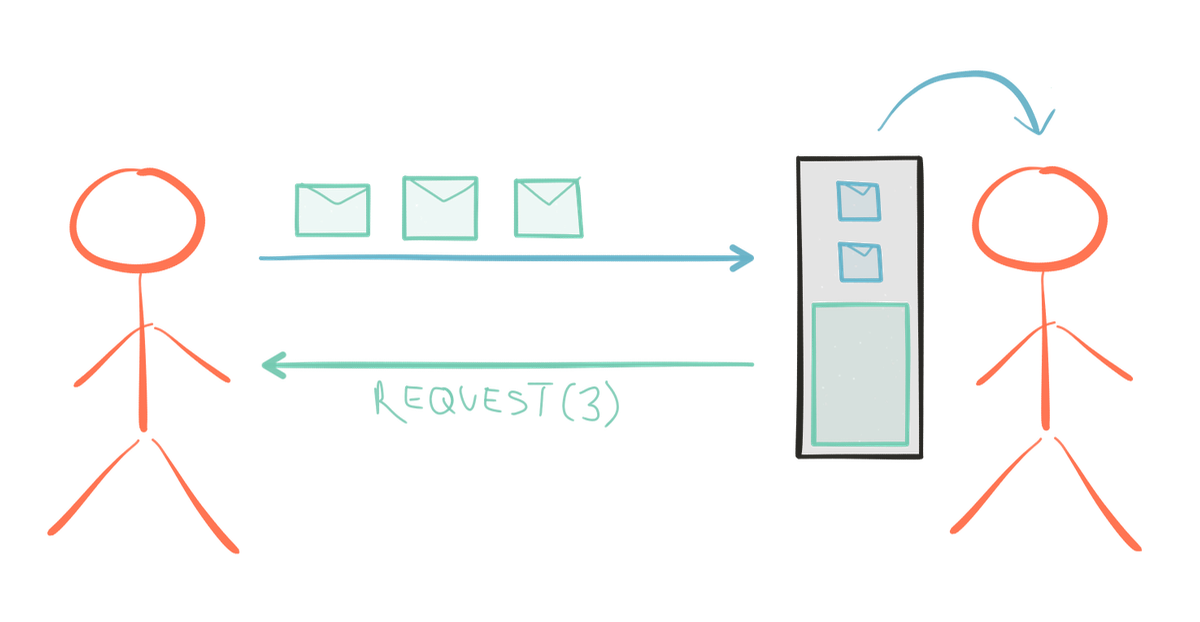
우리가 필요로 하는 것은 데이터의 양방향 흐름이다. 발행자에서 구독자로 다운스트림에 발행되는 요소들과 구독자에서 발행자로 업스트림에 발행되는 수요 신호(signal for demand). 구독자들이 수요 신호를 담당한다면 발행자들은 안전하게 원하는 요소 수만큼 안전하게 푸시할 수 있다. 이는 자원의 낭비를 방지한다; 수요 신호를 비동기적으로 보내기 때문에 구독자는 실제로 어떤 것을 받기 전에 더 많은 작업에 대한 많은 요청을 보낼 수 있다.
수요 신호는 다음 업스트림 단계에서 종료되지 않고 오히려 흐름을 통해 원래의 소스로 완전히 다시 흐른다. 전체 흐름을 통하는 배압(back pressure) 전파는 시스템에게 과도한 부하에 대응할 수 있는 기회를 준다; 어쩌면 특정 Reactive Stream 라이브러리는 다른 스레드의 새로운 구독자들을 이 구독자들간의 볼륨과 로드 밸런스 요소들을 처리하기 위해 스핀업하도록 제작되어 있다. 다른 라이브러리는 심지어 구독자들의 네트워크 클러스터간의 부하의 균형을 맞출 수도 있다. 이 탄력성(elasticity)의 유형은 당신이 선택한 라이브러리에 달려 있다; Reactive Streams는 라이브러리 개발자가 이것을 구현하는데 필요한 hook를 제공한다.
Reactive Streams는 실질적으로 푸시 기반이다. 가입자가 더 느릴 때는 풀 기반 시스템처럼 동작하고 가입자가 더 빠를 때는 푸시 기반 시스템처럼 동작하는 작업의 단일 모드를 제공한다. 이것은 동적이고 거의 실시간으로 변경된다. 이 동작을 이해하기 위해 Reactive Streams API를 살펴 보자.
전체 API는 다음과 같다:
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {}
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}
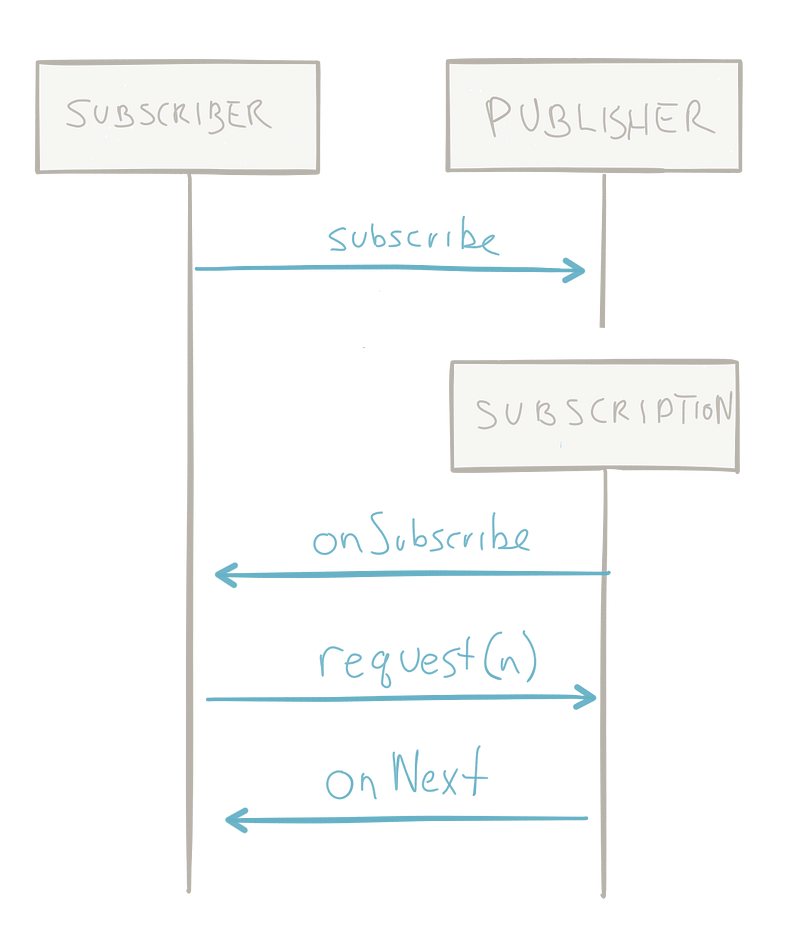
특히 흥미로운 점은 Subscription 인터페이스의 request(long n)이다. 이것이 구독자가 작업 요청 신호를 보내는 방식이다. 구독자가 request(1)을 호출하여 요청 신호를 보내면 이는 사실상 풀(pull)이다. 구독자가 request(100)처럼 발행자가 발행 할 준비가 된 것보다 더 많은 요소를 요구하는 요청 신호를 보내면 흐름이 푸시(push)로 바뀐다.
궁극적으로 배압(back pressure)의 제일 가치는 모든 호환 라이브러리들 간의 복원력(resilience)을 보장하는 것이다. 공통의 철학과 비전을 공유하는 라이브러리들간의 상호 운영성은 공통된 전략 없이는 거의 피할 수 없는 심각한 문제를 피하는데 도움이 된다.
배압(back pressure)의 부재는 결국 Out of Memory Exception(OOME)를 유발한다. 그렇게 되면 과부화된 시스템의 작업만이 아니라 안전하게 작업하고 있었던 것들까지 포함한 모든 것을 잃게 된다. — Jim Powers, Typesafe
“흐름을 따라 가자” 그리고 조금 더 깊이 들어가 보자. Reactive Streams의 호환 라이브러리들은 스트림을 선형 또는 그래프로 처리할 때 사용될 수 있다.
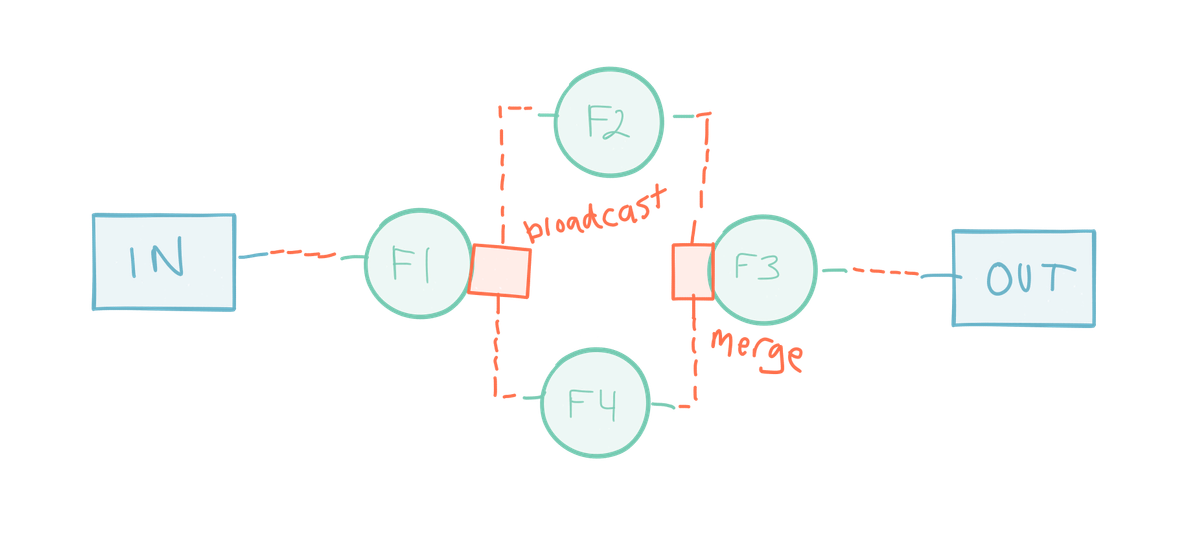
[그림:분할(split)과 결합(join)을 보여주는 단순한 그래프]
이 예제에서 함수 f1은 소스에서 들어오는 데이터에 적용된다. 소스는 어떤 것이라도 될 수 있다:
f1의 출력은 두 개의 하위 스트림으로 브로드캐스트(복제)되고 그 요소들은 f2와 f4로 처리된다. 이것을 분할(split) 또는 ““팬 아웃(fan out)”이라고 부른다. 그 뒤 두 함수의 출력은 f3에서 처리되기 전에 병합(merge)된다. 이를 “결합(join)” 또는 “팬 인(fan in)”이라고 부른다. 그런 다음 f3의 출력이 sink로 전송된다.
만약 당신이 프로그래밍없이 문제를 해결할 수 없다면, 당신은 프로그래밍으로 문제를 해결할 수 없다 - Klang’s Conjecture
위의 도표는 스트림으로 작업하는 것의 흥미로운 부수 효과(side effect)를 지적한다. 데이터, 그래프 그리고 흐름들은 스트림 처리 시스템을 설계하는 핵심이며 이는 우리가 소프트웨어로 해결하는 많은 문제들에 자연스럽게 부합한다. 위의 도표는 내가 수 년 동안 그린 “냅킨 뒷면” 스케치처럼 보인다.
다음은 Akka Streams을 사용해 스칼라로 청사진을 구현한 것이다. 이 글은 Akka Streams에 대한 심층적인 튜토리얼이 아니므로 다음 문법이 생소해 보이더라도 참길 바란다. 이 코드를 실행하고 싶다면 Akka Streams를 시작하는 데 필요한 모든 것이 포함 된 Typesafe Activator를 다운로드하라.
object GraphExample {
import akka.actor.ActorSystem
import akka.stream.ActorMaterializer
import akka.stream.scaladsl._
import FlowGraph.Implicits._
import scala.util.{ Failure, Success }
import scala.concurrent.ExecutionContext.Implicits._
implicit val system = ActorSystem("Sys")
implicit val materializer = ActorMaterializer()
def main(args: Array[String]): Unit = {
val out = Sink.foreach(println)
val g = FlowGraph.closed(out) { implicit builder =>
sink =>
val in = Source(1 to 10)
val bcast = builder.add(Broadcast[Int](2))
val merge = builder.add(Merge[Int](2))
val f1, f2, f3, f4 = Flow[Int].map(_ + 10)
in ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink.inlet
bcast ~> f4 ~> merge
}.run()
// ensure the output file is closed and the system shutdown upon completion
g.onComplete {
case Success(_) =>
system.shutdown()
case Failure(e) =>
println(s"Failure: ${e.getMessage}")
system.shutdown()
}
}
}
Scala에 친숙하지 않은 사람들을 위해 다음 두 줄을 제외한 나머지 대부분의 코드를 무시하자.
in ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> out
bcast ~> f4 ~> merge
이 코드 라인들이 청사진과 얼마나 비슷한 지를 확인하라. 이는 배관(plumbling)에 대해 생각하기 보다 문제에 대해 생각하기 위한 강력한 추상을 개발자에게 제공한다. 예를 들어 ETL 시스템은 이미 매우 유사한 방식으로 설계되어 있다 –그것들은 다양한 출처의 데이터를 수집하고 값들을 조작하며 결과의 일부 타입을 출력한다. 가장 큰 차이점은 이 시스템들을 정의하는 코드는 배관(plumbling)에 관련으로 가득차서 해법 자체를 보기 힘들게 한다는 것이다. 또한 스트림 기반 시스템이 거의 실시간으로 데이터를 수집하는 반면 그것들은 멈춰진 상태에서 데이터를 수집한다.
Reactive Streams 구현들
당신만의 스트림 처리 시스템을 만들 준비가 되었다면 라이브러리를 선택할 필요가 있을 것이다. Reactive Streams 명세의 구현은 서로 호환되며 이는 Reactive Streams 호환 라이브러리 선택의 명백한 장점이다. 명세를 준수하는 한 다른 라이브러리들을 사용하는 스트림 처리 시스템들을 통합할 수도 있다.
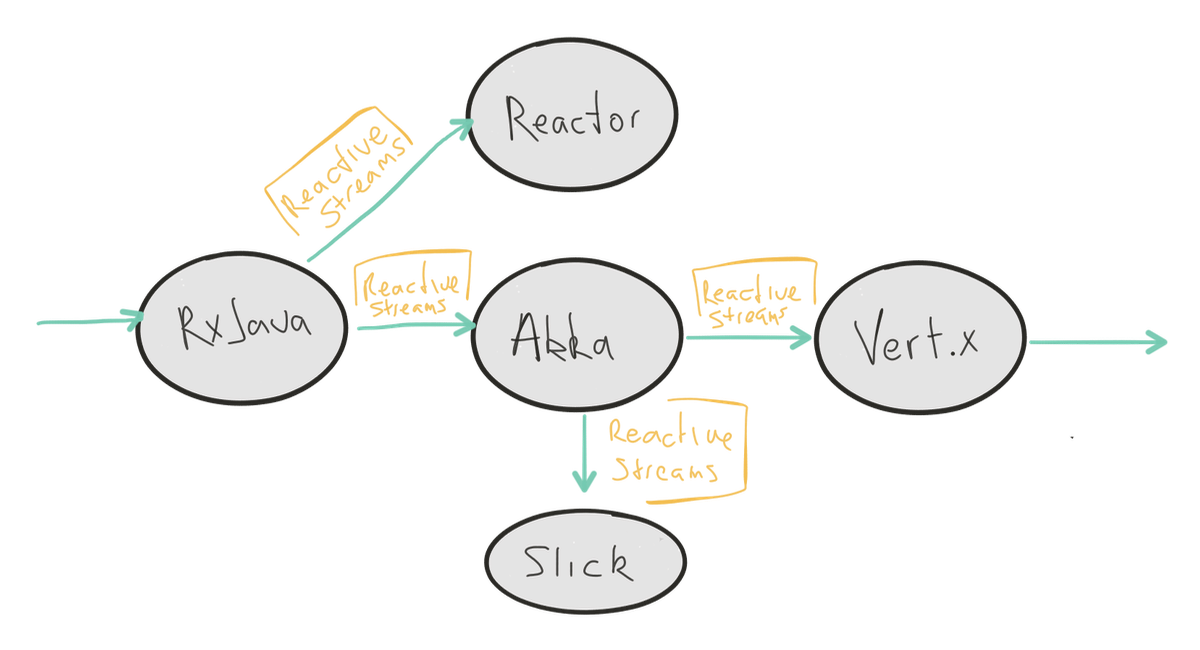
[그림:Reactive Streams은 접착제이다. 호환 라이브러리들은 Reactive Streams 프로토컬을 통해 의사소통한다.]
몇 가지 Reactive Streams의 구현은 다음과 같다:
스트림의 전반적인 개념적 개요와 Reactive Streams 명세를 통해 당신은 차세대 시스템을 만드는 것에 한 발 더 가까이 다가서게 된다. 새로운 도구 세트를 선택하는 것은 소프트웨어를 만드는 방법에서 훨씬 더 큰 변화의 작은 부분일 뿐이다. 혁신은 대담하고 결정적인 행동이 필요하다. 그것은 학습이 필요하다. 상상력이 필요하다. 변화가 필요하다.
비동기 경계는 시간상의 분리에 관한 것이지만 Reactive Streams가 아직 우리에게 주지 않는 것은 공간의 분리이다 – 분산. 이는 이상적으로는 위치 투명성(location transparency)으로 노드들과 클러스터간에 부하를 분산할 수 있게 한다. 이 용어들이 생소하다면 작년에 작성했던 반응형 프로그래밍에 대한 글을 읽어 보라.
Spark Streaming, Cassandra 와 Kafka같은 라이브러리들이 명세를 구현하기 시작할 때 미래는 더욱 흥미로워 질 것이다. 우리는 아직 그곳에 없지만 스트리밍으로의 이동은 피할 수 없는 것이다. 앞으로 이것들 그리고 더 많은 라이브러리들이 Reactive Streams 호환이 되는 것을 보더라도 놀라지 않을 것이다.
Akka Streams을 더 탐구하는 이 시리즈의 다음 파트, Diving into Akka Streams를 확인하길 요청한다.
지금 당장 코딩을 시작하기를 원하면 당장 Typesafe Activator를 다운로드하는 것을 매우 권장한다. 여기에는 유용한 튜터리얼을 포함하여 Akka, Play 그리고 Scala를 시작할 때 필요한 모든 것이 포함되어 있다.
About The Author
Kevin Webber is CEO of RedElastic, a boutique consulting firm that helps large organizations transition from heritage web applications to real-time distributed systems that embrace the principles of reactive programming.
He was formerly Enterprise Architect and Developer Advocate at Lightbend.
In his spare time he organizes ReactiveTO and Programming Book Club Toronto. He rarely writes about himself in the third-person, but this is one of those moments.